
サイバーエージェント、225億パラメータの日本語LLMを公開 Llama-3に匹敵
【東京本局 = テクノロジー】サイバーエージェントは9日、225億パラメータを持つ日本語大規模言語モデル(LLM)「CyberAgentLM3-22B-Chat」を一般公開した。既存のモデルを基にせず、一から開発する「スクラッチ」を採用した。一部の性能テストでは、米Metaが開発した700億パラメータの「Meta-Llama-3-70B-Instruct」と同等の性能を叩き出した。

サイバーは昨年5月、最大68億パラメータの初モデルを公開し、同年11月には後継となる「CyberAgentLM2-7B-Chat」をリリースした。CyberAgentLM2では、日本語約50,000文字を一度に処理することができるようにした。
今回公開した「LM3」は、前モデルの「LM2」の後継で、パラメーターは225億。LM2から3倍以上の規模に拡大した。パラメータとは、AIモデルが学習した知識や言語の特徴を数値化したもので、一般的に数が大きいほど高度な処理が可能になるとされている。より複雑な日本語の理解や生成が可能になる。
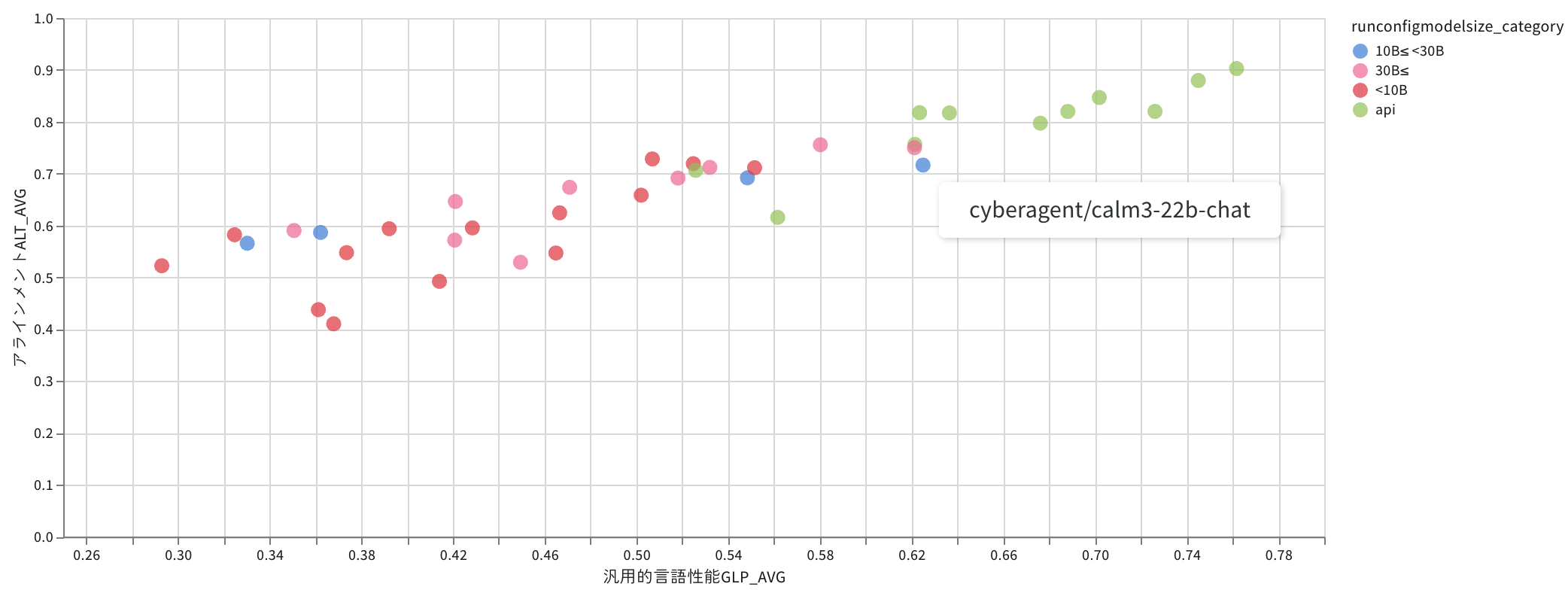
LM3は既存モデルをベースに用いずにスクラッチ開発した。スクラッチ開発とは、既存の基盤を使わず一から新しく開発することを指し、高度な技術力が必要とされる。LM3は、生成AIの日本語能力を評価するNejumi LLMリーダーボード3で、700億パラメータの「Llama-3」と同等の性能を発揮した。スクラッチ開発の日本語LLMとしてはトップクラスだ。
サイバーは「日本語に特化したLLMの開発は、日本の自然言語処理技術の発展に不可欠。今回のモデル公開により、より多くの企業や研究者が最先端のAI技術にアクセスできるようになることを期待している」とコメントした。
同社は「極予測AI」など、自社サービスでLLMを活用しており、今後は新モデルを用いたさらなる機能強化を図ると見られる。同社が得意とする広告事業との連携が期待される。
日本語LLMの開発は加速している。ELYZAは米Metaのオープンソースモデル「Llama3」をベースに日本語性能を強化したLLMを開発し、性能が「GPT-4」を超えたと報告している。また、NECも130億パラメータの日本語特化型LLM「cotomi」を開発するなど、競争が激しくなっている。
政府も日本語AI開発を後押しする。総務省傘下の情報通信研究機構(NICT)は、9テラバイトにも及ぶ大規模な日本語データセットを整備し、KDDIとの共同研究で日本語特化型LLMの開発を進めている。NICTのデータセットは、米OpenAIの「GPT-3」の2倍以上の規模を持ち、ほぼ全てが日本語データで構成されているという。
Googleの元従業員らが日本で起業したSakana AIは、創業1年経たずで企業価値10億ドルを超え日本最速でユニコーン企業に登り詰めるなど、AI開発への投資も加熱している。東京大学松尾研究室を中心としたスタートアップの設立も相次いでおり、AI開発の裾野が広がっている。今後は、採算性の確保や膨大な資金を持つ米国ITと闘えるかが成功の鍵を握る。

当サイト掲載情報について、法的請求がある場合…お問い合わせへ
当サイト掲載情報について、不備や依頼等がある場合…メール、Twitter DM等